Resource Discovery & Query¶
Lakesuperior offers several way to programmatically discover resources and data.
LDP Traversal¶
The method compatible with the standard Fedora implementation and other LDP servers is to simply traverse the LDP tree. While this offers the broadest compatibility, it is quite expensive for the client, the server and the developer.
For this method, please consult the dedicated LDP specifications and Fedora API specs.
SPARQL Query¶
A SPARQL endpoint is available in Lakesuperior both as an API and a Web UI.
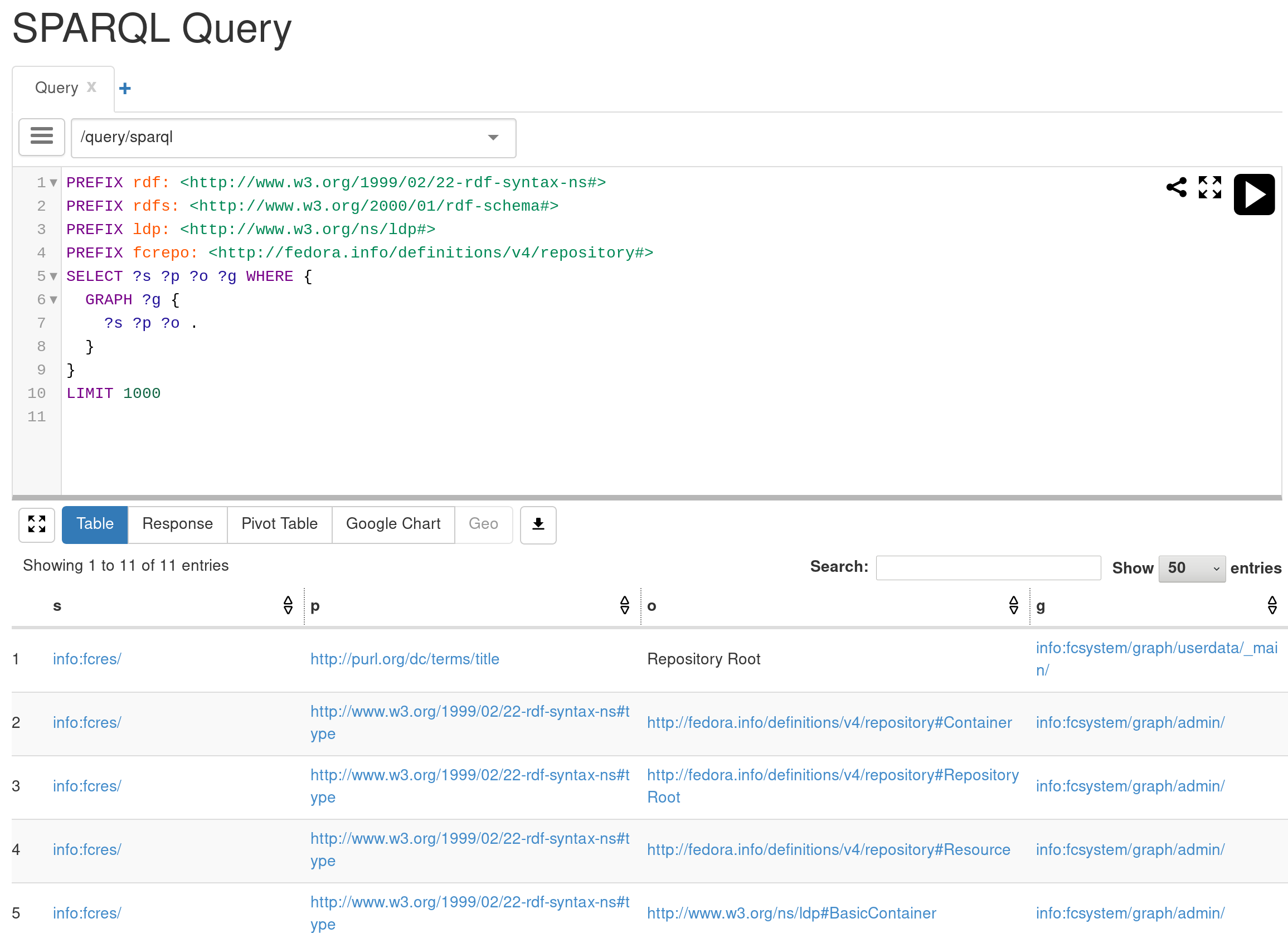
Lakesuperior SPARQL Query Window
The UI is based on YASGUI.
Note that:
- The SPARQL endpoint only supports the SPARQL 1.1 Query language. SPARQL updates are not, and will not be, supported.
- The LAKEshore data model has an added layer of structure that is not exposed through the LDP layer. The SPARQL endpoint exposes this low-level structure and it is beneficial to understand its layout. See Lakesuperior Content Model Rationale for details in this regard.
- The underlying RDF structure is mostly in the RDF named graphs. Querying only triples will give a quite uncluttered view of the data, as close to the LDP representation as possible.
SPARQL Caveats¶
The SPARQL query facility has not yet been tested thoroughly. the RDFLib implementation that it is based upon can be quite efficient for certain queries but has some downsides. For example, do not attempt the following query in a graph with more than a few thousands resources:
SELECT ?p ?o {
GRAPH ?g {
<info:fcres/my-uid> ?p ?o .
}
}
What the RDFLib implementation does is going over every single graph in the
repository and perform the ?s ?p ?o query on each of them. Since
Lakesuperior creates several graphs per resource, this can run for a very long
time in any decently sized data set.
The solution to this is either to omit the graph query, or use a term search, or a native Python method if applicable.
Term Search¶
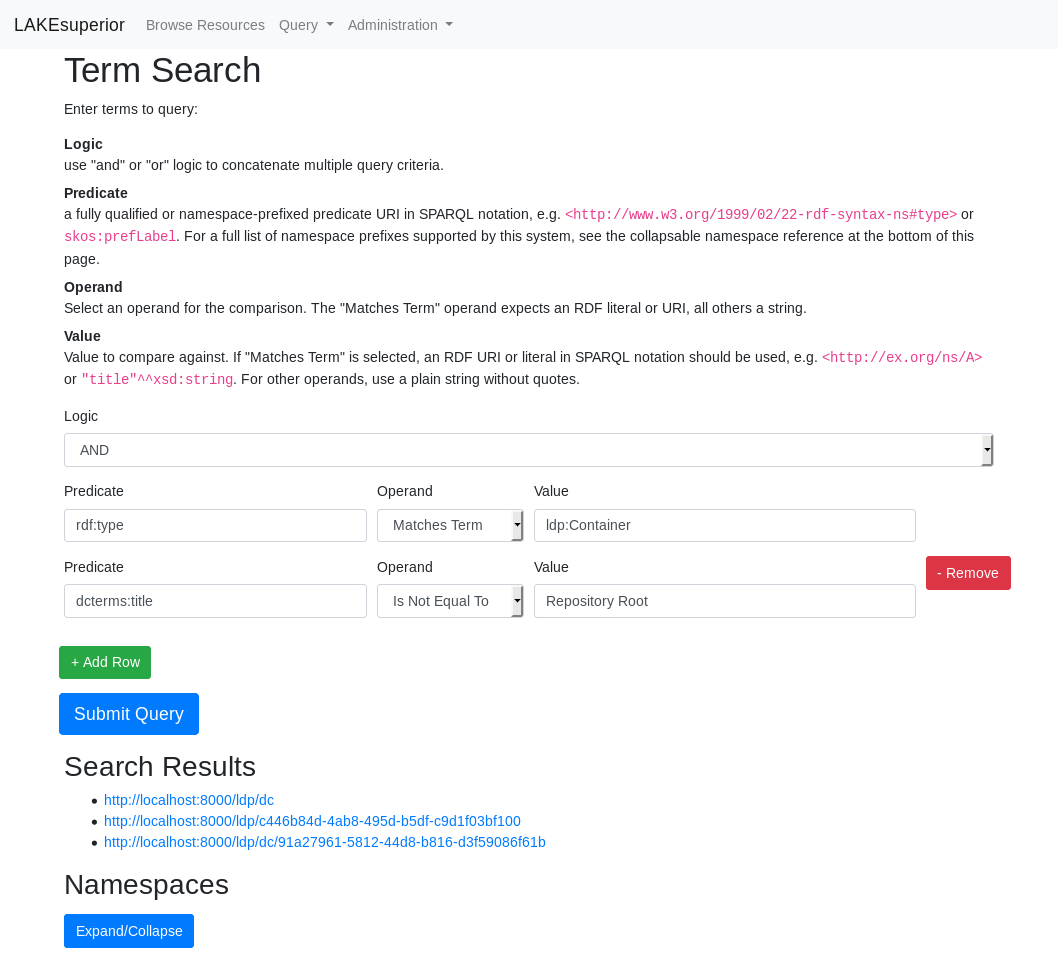
Lakesuperior Term Search Window
This feature provides a discovery tool focused on resource subjects and based on individual term match and comparison. It tends to be more manageable than SPARQL but also uses some SPARQL syntax for the terms.
Multiple search conditions can be entered and processed with AND or OR logic.
The obtained results are resource URIs relative to the endpoint.
Please consult the search page itself for detailed instructions on how to enter query terms.
The term search is also available via REST API. E.g.:
curl -i -XPOST http://localhost:8000/query/term_search -d '{"terms": [{"pred": "rdf:type", "op": "_id", "val": "ldp:Container"}], "logic": "and"}' -H'Content-Type:application/json'